Hey folks! I've spent the past quarter working on jank's error messages. I've focused on reaching parity with Clojure's error reporting and improving upon it where possible. This has been my first quarter spent working on jank full-time and I've been so excited to sit at my desk every morning and get hacking. Thank you to all of my sponsors and supporters! You help make this work possible.
The state of Clojure's error reporting
Before we talk about jank, let's talk specifically about Clojure. The community wants Clojure's error reporting to improve. In the yearly State of Clojure survey, error reporting is consistently at the top of areas where improvement is desired. This applies not only to 2024's results. It goes all the way back to the first 2015 results. With the work I've been doing the past quarter, I have tried to find reasons why Clojure's error reporting can't be world-class. Let's take a look at what I've built and you can be the one to decide.
Starting from zero
Three months ago, jank's error messages were abysmal. Far worse than Clojure's. The main thing I focused on, while building out jank's functionality, was that errors were raised. Not that they were helpful, just that they were raised. Let's take a more concrete look at where we started. We'll start by using this Clojure code, which has a keyword instead of a symbol for a def.
(def :foo 2)Three months ago, we'd get this from jank.

This was bad for a few reasons. Most importantly, we don't get any useful source information (file, line, column) for where the error happened. The error could be in the file we're running or in some dependent file. This wasn't helpful. I knew that, though. I just hadn't spent any time on it. Let's take a look at what Clojure gives us for the same file.

Ok, this is more helpful. We get the file name, line, and column. The rest of the info, on the first two lines, is largely the same as what jank provided. Clojure also provides a "full report" which, in this case, is 50 lines of EDN saying the same thing, but also with a JVM stack trace.
So, we know the minimum info we need in order to make a useful error message. We see what Clojure provides. Given the same file, jank will now report this.
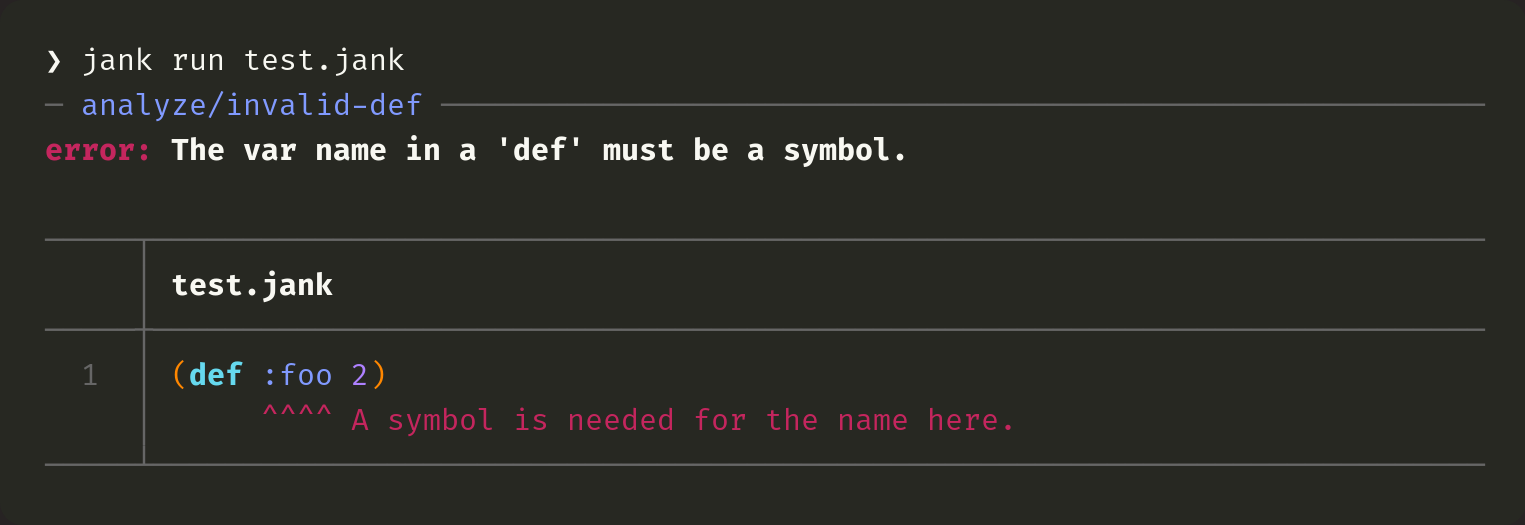
It's beautiful! There's a ton going on behind the scenes. Let's pick apart all of the pieces and understand how we've improved upon Clojure.
Source information
A typical compiler will lex, parse, and then semantically analyze the program. Lexing breaks the source into tokens and the compiler can keep track of the source info for those tokens. Parsing takes a stream of those tokens and turns it into language constructs, like function calls, maps, vectors, etc. The source information can be maintained, as the parse tree is being built, so that each parsed form knows where it came from. Then, when we semantically analyze those forms, we can point back to the source if we find issues.
In a lisp, like Clojure, this becomes a problem. After lexing, Clojure's parser will turn the tokens into Clojure data like lists, vectors, maps, etc. That's the parse tree. There is no separate data structure for it. This is incredibly powerful, since it allows the analyzer to treat any Clojure data as code, which is what enables code-as-data macro systems to work. It also introduces some limitations, though. If you want to maintain source information in the parsed objects, you either need some way of mapping back to an alternative parse tree which has that info or you need a way to tack it onto your Clojure objects. Clojure uses the latter, via metadata. Many objects in Clojure support metadata, which is just a map which anyone can cram things into. The compiler will automatically put some source info into an object's metadata. Then, during semantic analysis, it can have an idea of where the parsed objects live in the original source.
The key problem, though, is that many objects support metadata. Not all objects. So, the objects which don't support metadata end up with no source info. The compiler can't actually directly find out where in the source file they came from. For example, numbers like integers and doubles don't support metadata. This is likely for performance reasons, to keep them small. Keywords don't support metadata since they're interned (allocated once and deduped). So every keyword :foo in your source file actually maps to one object.
Reparsing
I'm going to keep focusing on this same (def :foo 2) example for now, since it's such a good one. When we look back at Clojure's error output, we see that it showed some file/line/column information, but it said the error happened a line 1, column 1. Arguably, the error is that :foo needs to be a symbol. Sure, the problem started at line 1, column 1, with the start of the (def, but the most helpful place to point is at :foo. As we discussed, though, :foo doesn't have any metadata, so we have no source info for it! How do we find out where :foo actually is?
There are different ways you could go about this, but the most compelling option I found was to go back to the source and reparse. In our case, (def :foo 2) exists in a list and lists have metadata. That means we have the source info for the list and we know that :foo is the second form in the list. So jank will actually go back to the file, start lexing again, at the list, and read the second form in there. With that, we'll have the full source info for :foo so we can properly point at it.
Thanks to Ambrose Bonnaire-Sergeant, creator of Typed Clojure, who originally suggested this reparsing approach to me during a brainstorming call. It saved me from having to go down some undesirable roads.
A nice UI
Let's take a step back for a bit and talk about how I approached this quarter. At the start, I mocked up some sample errors and showed them around for feedback. Before I did that, even, I made a list of all the important parts I wanted to include. The main items for the UI were:
- Human-readable error ids (thanks to Dustin Getz for the suggestion)
- Precise source information (like we talked about above)
- Highlighted code snippets
- Notes identifying errors and other relevant forms
Let's look at a more interesting example which demonstrates all of these.
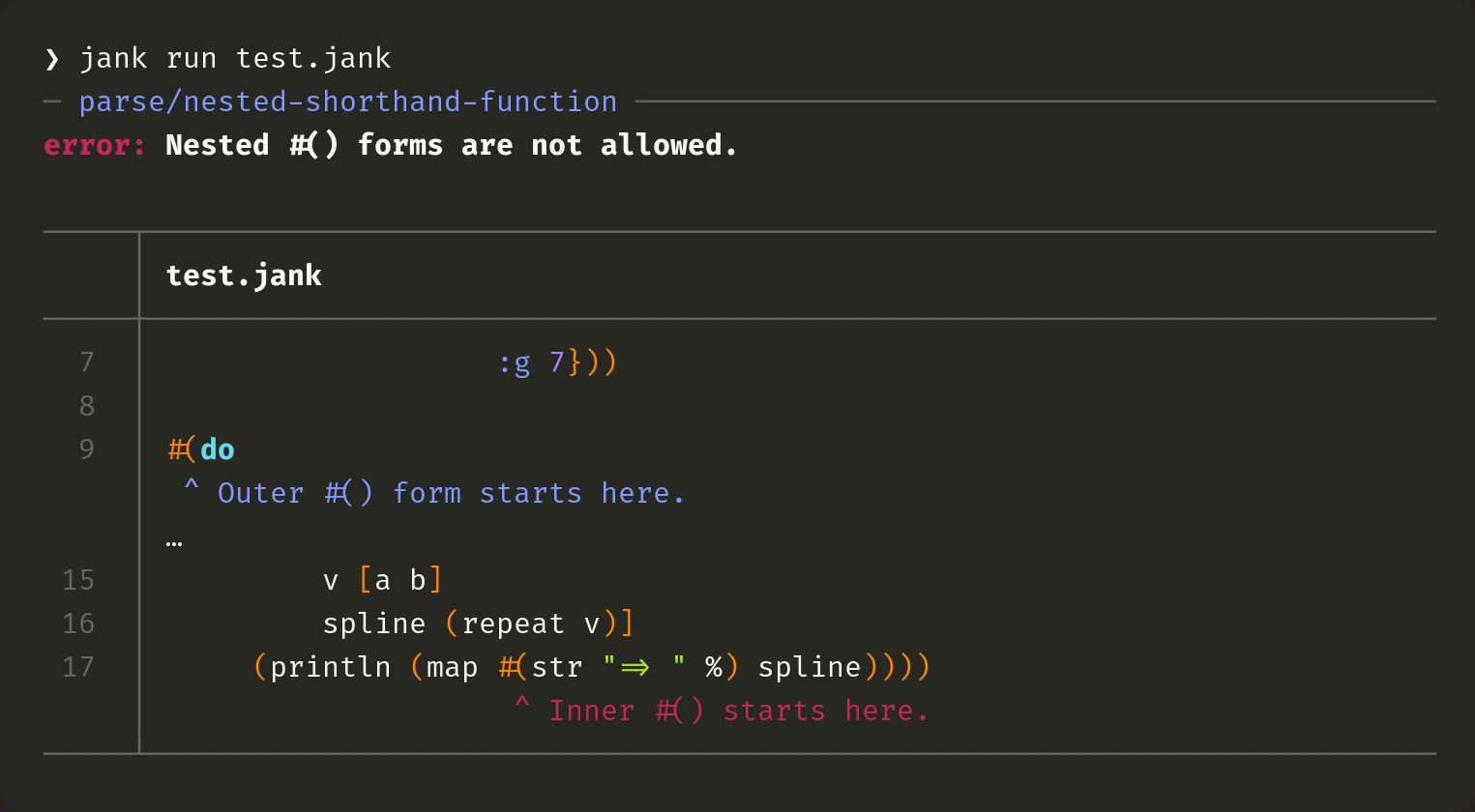
Each error has an id which is the first thing you see (parse/nested-shorthand-function). In the future, jank will have a dedicated web page for each of these, on the jank website. The web page will expand on the explanation, provide examples, and suggest common fixes. This should be the first result in your web search for the error.
Next, we point exactly where the nested #() form starts and we show it in a highlighted snippet. We also point at the outer #() form which is preventing the inner #() form from being valid. Note, there are lines between 9 and 15 which are collapsed, since they're not relevant. We're optimizing for showing the most important bits of code for you to understand and fix the issue.
Let's see what Clojure does, given the same source.
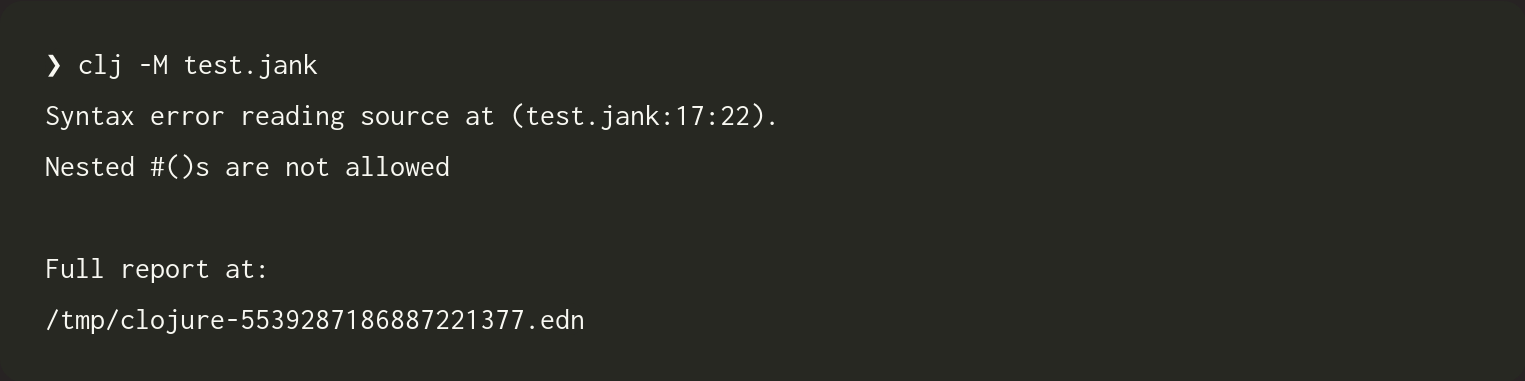
In our first example, (def :foo 2), Clojure was unable to present precise source info. In this example, however, it does. The nested #() form is at line 17 and reasonably starts anywhere from column 20 to 22. However, Clojure doesn't provide a human readable error id, code snippets, or any other relevant information, such as the location of the outer #() form.
Graceful lexing
The highlighter for jank's code snippets is based on jank's lexer. However, we run into a problem of needing to highlight source code which we know, in some way, is incorrect. If it weren't incorrect, we wouldn't be showing an error with a code snippet. Unfortunately, the code could be so incorrect that it doesn't correctly lex. We gracefully handle this by skipping the highlighting for such tokens and resuming highlighting with the next valid token.
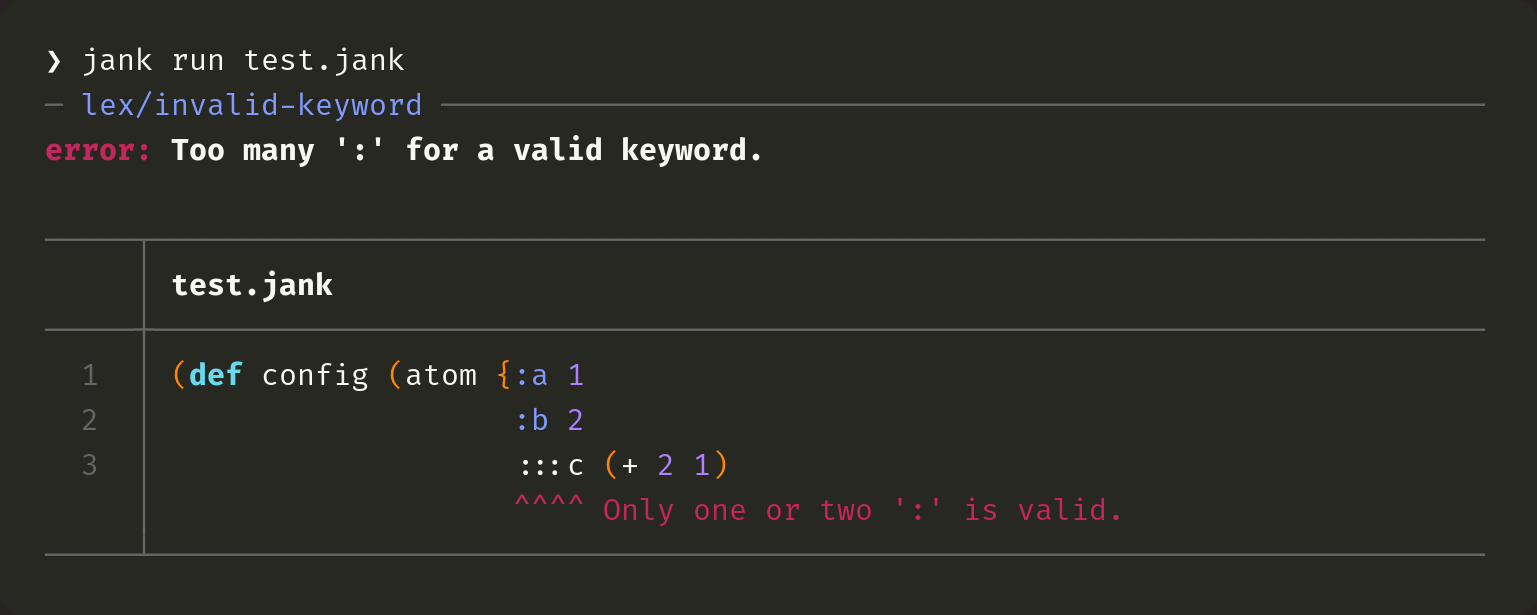
In Clojure, you can have :c or ::c, but you may not have :::c. Our error message indicates there are too many : and our note spells out exactly what is supported. Let's see what Clojure does with the same source.
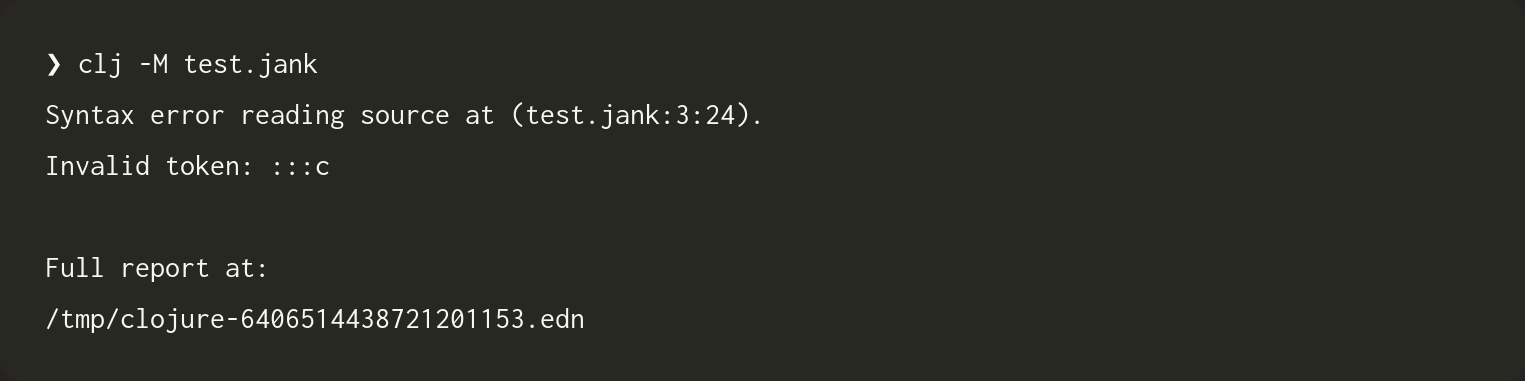
This is the first time Clojure has repeated the source back to us, in any form. I think that's helpful! Clojure gets the source info somewhat right, but it actually points after the :::c. That's close enough to be useful, though.
JAR sources
Clojure doesn't treat JAR sources specially, when reporting errors. In fact, it'll just show the leaf name of a file and leave it up to you to figure out if that file is in a JAR or not. When half of my Clojure files are called core.clj, this ends up being a problem, so I wanted to tackle it in jank. Let's assume we have a nice lib we want to use, called mylib. We set up a small Clojure file to use it and try calling one of its functions.
(ns test
(:require [mylib]))
(mylib/foo)Ah, but mylib actually has a bug.
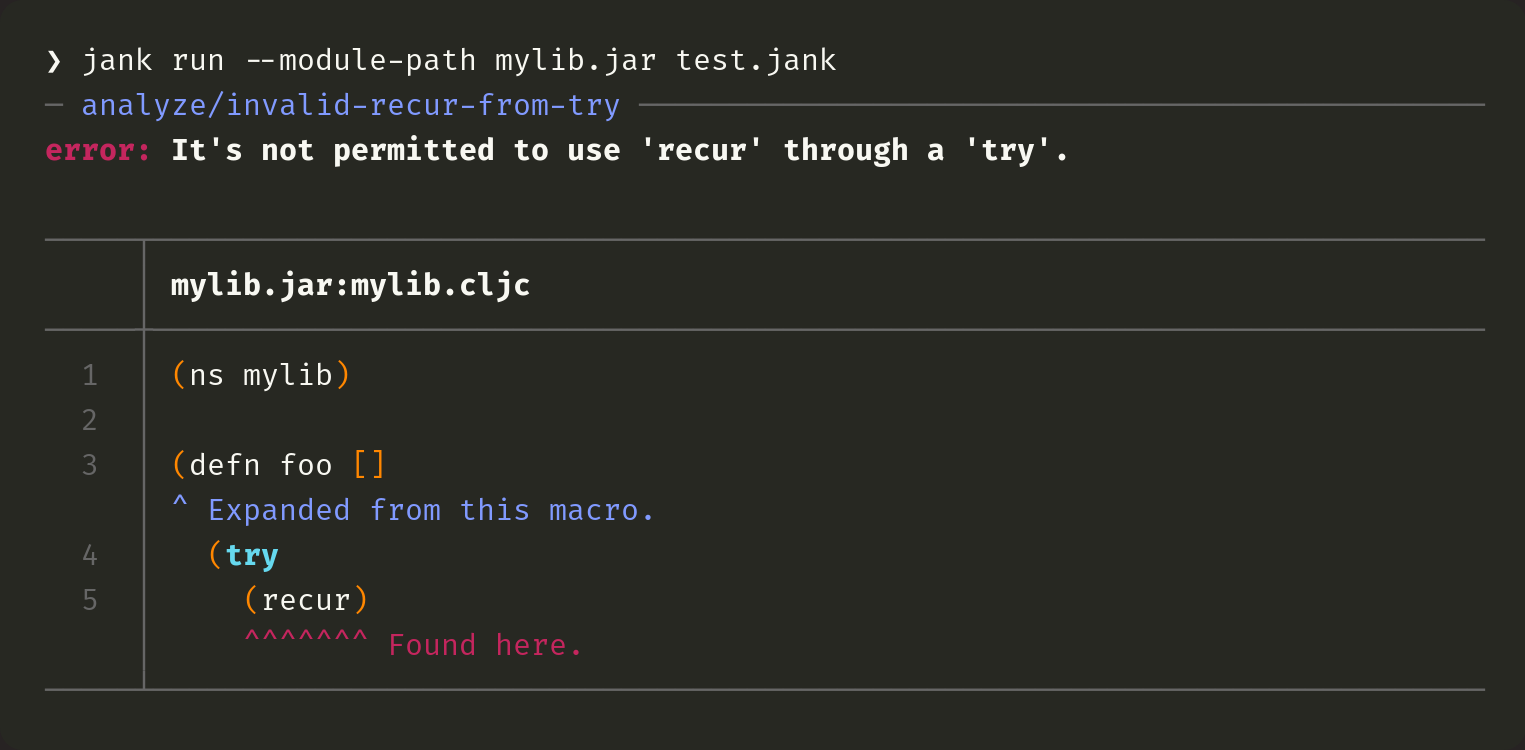
Ignore the macro expansion bit. We're not there yet. 😁 So mylib is trying to use recur from within a try, which is not supported. Here, jank should be pointing at the try to say where it starts. That would be more helpful and I have a TODO in the code for it. But note this: we're treating the JAR file specially, by showing its JAR path and then the file path within the JAR. Here's what Clojure shows, given the same sources (quite the mouthful of a command).
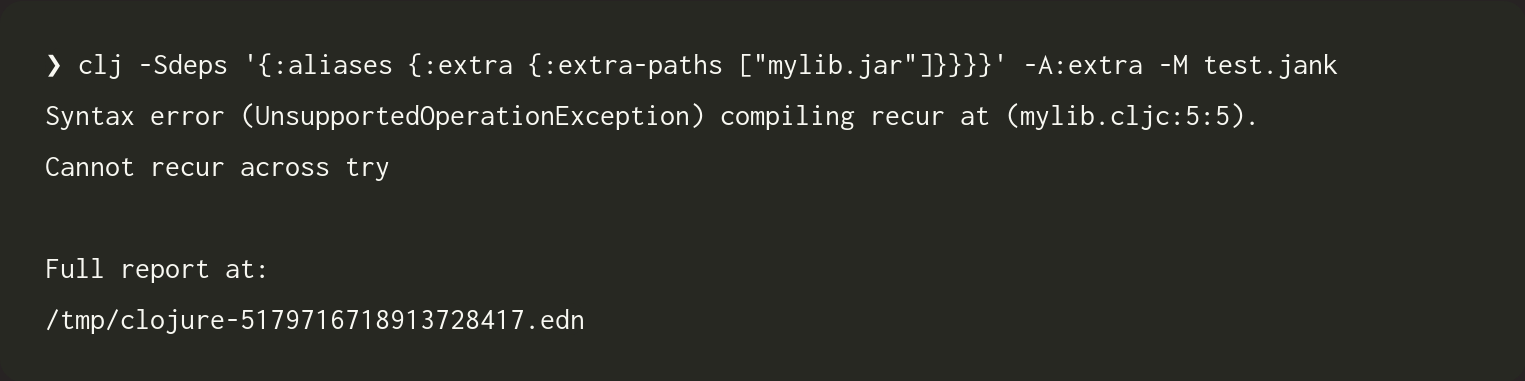
Support jank
I hope that this post, so far, demonstrates the level of quality I produce and my attention to detail. I hope that reading about jank gets you excited for the possibilities of Clojure, not only in terms of a native runtime and C++ interop, but also general niceties like world-class error reporting.
If I've hit the mark here, please consider sponsoring me. I ultimately want to build a non-profit jank software foundation, hire others to help full-time, and give back to the software which makes jank possible. Before that, though, I need to prove it's viable for me alone to do this full-time. If you love what I'm building, please chip in $10/m to help make this dream possible. This year, we're going to release the first alpha for jank.
Thank you! Back to the post. 🙂
Macros
There's another huge snag, when it comes to reporting errors in a lisp. Tons of the familiar constructs we use every day are actually macros which generate code for us. In Clojure, that includes defn, fn, let, loop, when and more. In order to be able to provide precise error messages, we need to track source information as it moves through macros. Let's take a look at what I mean.
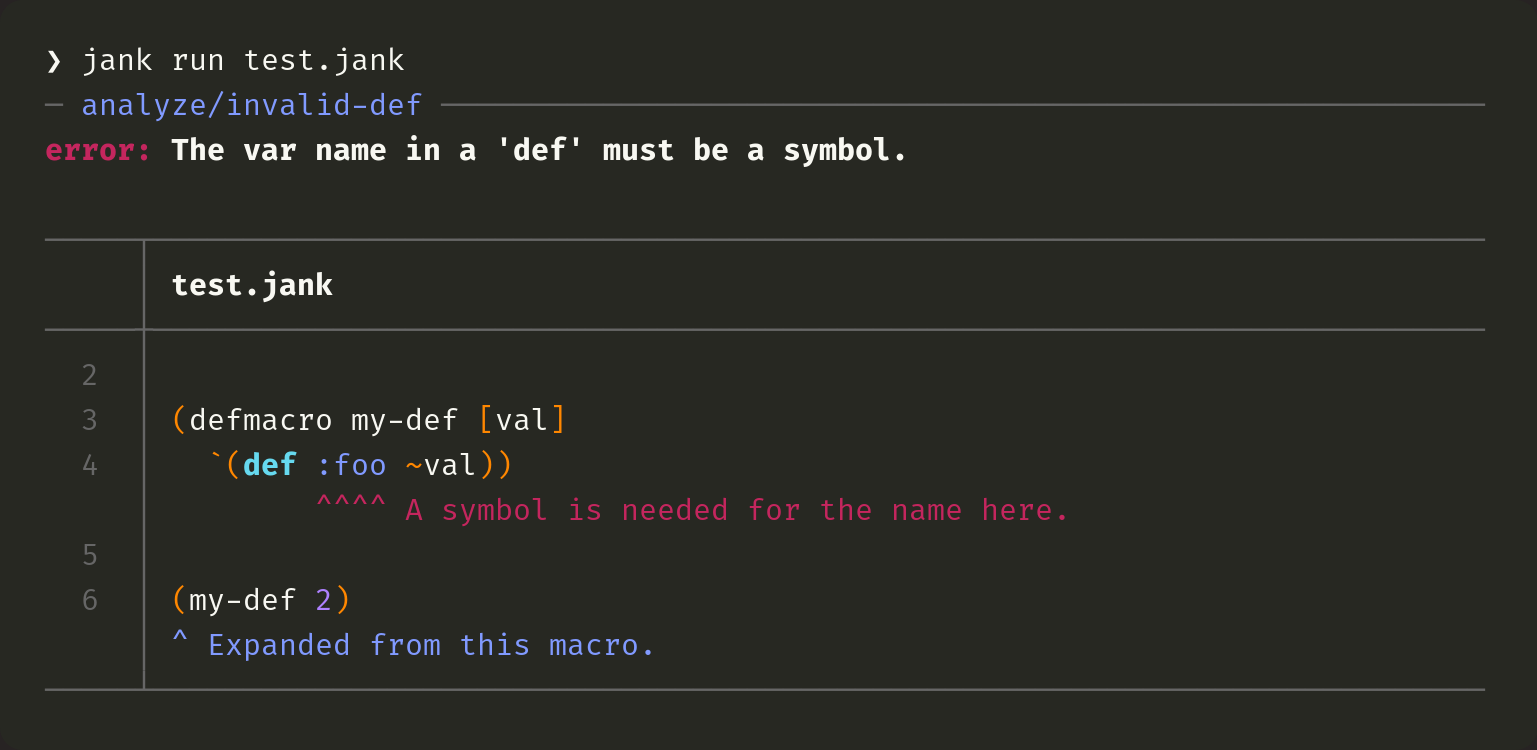
Here we have a macro which has a bug in it. The def which it generates uses :foo as the name, but it has to be a symbol, not a keyword. Now, we called this macro on line 6, but jank determines that the error is actually due to the :foo on line 4. This is because it uses reparsing from the def to find :foo. However, it can only do that because jank keeps track of the source info on syntax quoted forms, so that the syntax quoted list for def can be used to find the name within. Clojure doesn't do this.
If we were to give this to Clojure, it would only point out where the macro was first called. Clojure doesn't point to any sources within macros.

This is where jank really starts to shine. We provide the same info as Clojure, but take it a step further because we know more about syntax quoted sources. However, jank is still working on limited info, in this example, since it doesn't have the source information for :foo and needs to reparse it. If we actually have the source information, we can provide even more info.
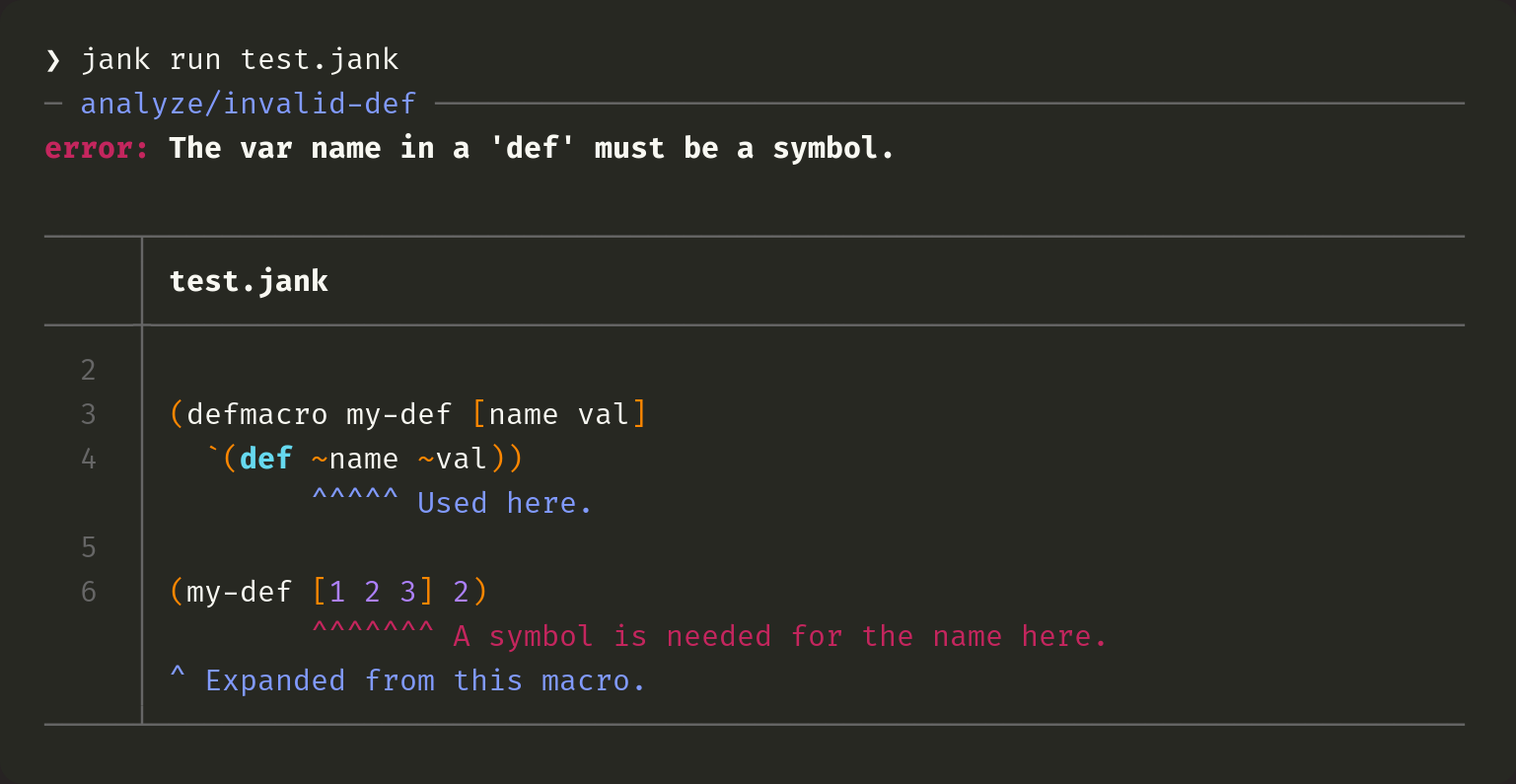
Here, we know where [1 2 3] comes from, but we also track where it's used in the macro. This is incredibly powerful, since it allows us to point at both of these locations. Clojure just shows the same thing as it did in the previous example, only pointing at line 6 where the macro expansion happens.
jank keeps track of the original form of macro expansions, so when we're analyzing some code, we can know where it came from. This is a stack, though, since one macro can expand into code which uses another macro, which expands into more code which uses other macros, and so on. We need to intelligently show only the "right" macro, in the source code, even though jank has access to the entire stack. For example, in the following code, we're using macros like let, when, and fn in both the outer source and in the syntax quoted list. jank will know that we only want to point at the expansion on line 10, though.
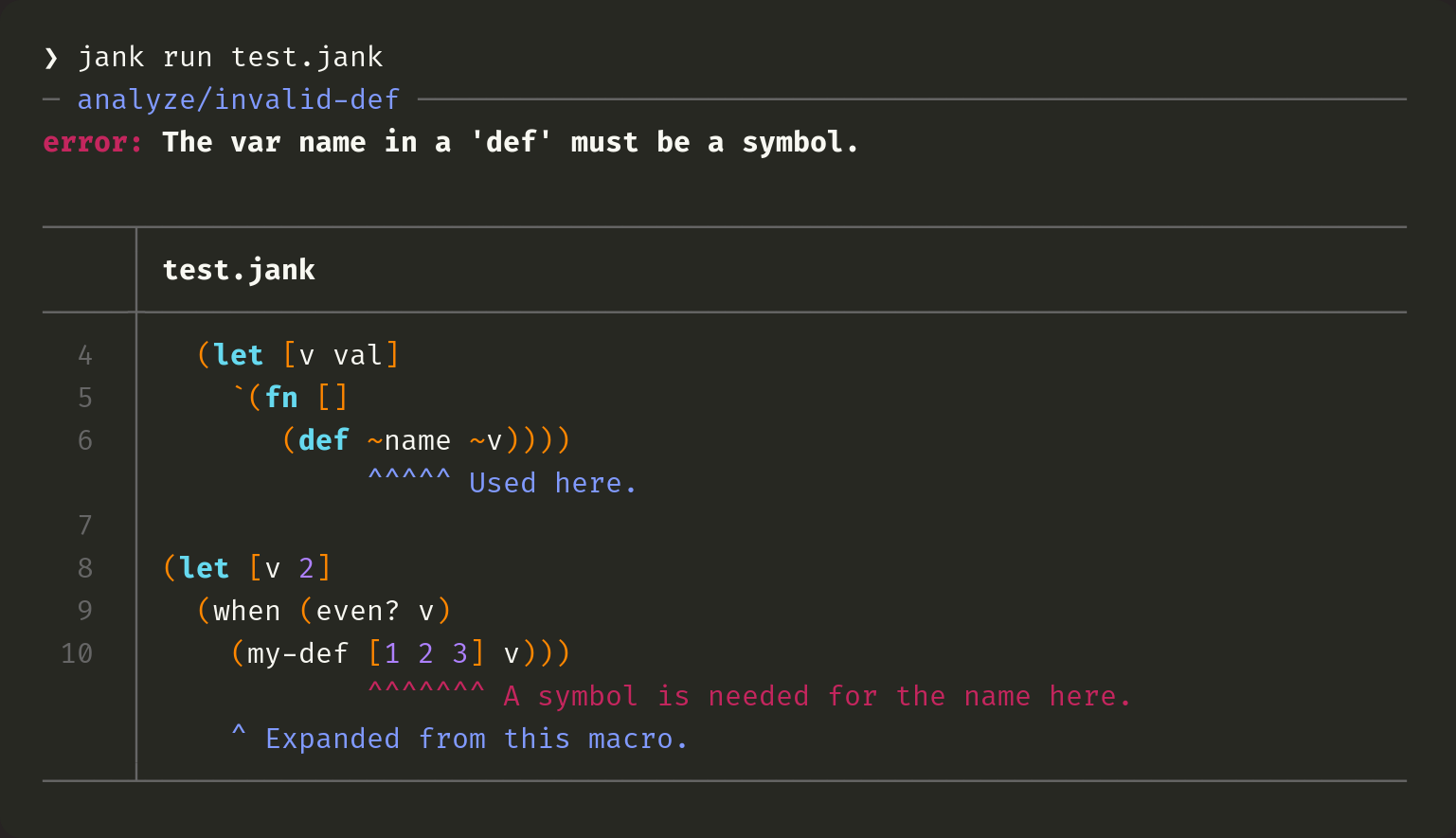
This is one area of the error reporting which I didn't think would be possible. To its credit, Clojure does a great job at always pointing directly at the latest macro expansion, too. It just lacks all of the nuance of being able to say what went wrong in the macro itself.
Synthetic macro data
Not all macros use syntax quoting, which means not all returned macro data will have source info. In those cases, jank will be unable to refer to where particular data is used. For example, taking our my-def macro from above, we can return synthetic data instead. That just means we return (list 'def name val). The error which jank reports will not point at name within the macro, since there's no source trail to get us there.
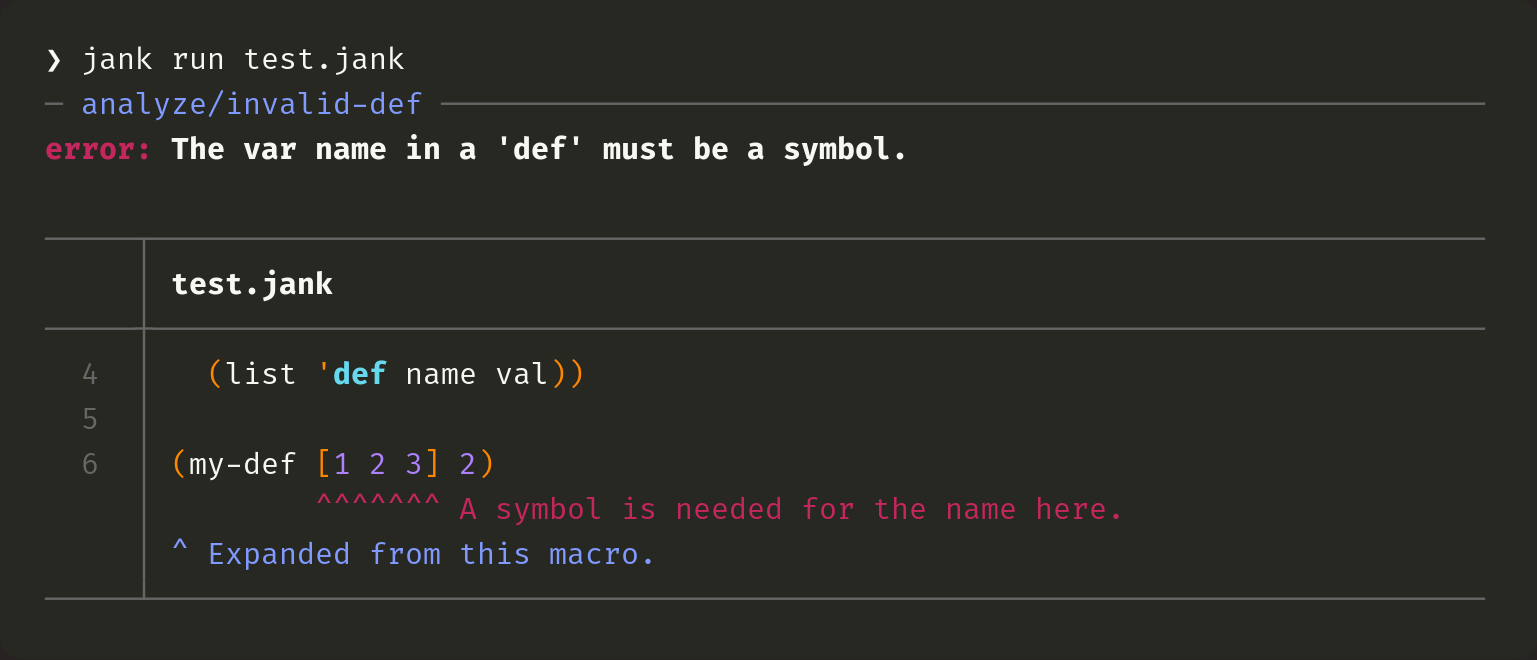
To get the best error reporting possible, use syntax quoting whenever you can, in macros.
A different approach to understanding errors
This style of reporting may seem odd to you. When I showed a friend of mine, he was concerned that it's not just pointing him at one place to start his search. I think we've been trained to think like that because our tooling has been poor. What I really want is to be given a snapshot of information, connecting all of the relevant bits of code, so that I can understand the source of the problem more quickly. That's why jank shows multiple notes together, in one snippet. It's about framing a picture and highlighting the key areas. I love it.
Runtime errors
Once your program is written and properly compiling, we're not out of the error reporting business yet. jank and Clojure are still responsible for reporting uncaught exceptions. There are actually a few interesting cases here, so let's break it down.
- Typical run-time exception - Some part of your code, or your dependencies, threw an exception you didn't catch. This happened as part of a REPL evaluation or AOT program execution.
- Macro expansion exception - This is arguably a run-time exception which happens at compile-time, since macros bridge the gap between those two worlds.
- Compile-time exception - If you call
evalat run-time, to compile some code, and there are issues in that code, the compiler error is thrown. This is a compile-time error thrown at run-time.
Let's take a look at each of these in turn, since the way we handle them is slightly different.
Typical run-time exception
When an exception is uncaught at run-time, Clojure will print a stack trace. We've all seen these, I'm sure. In C++, there's no standard way of printing a stack trace. There's a new <stacktrace> API added to C++23, but it lacks widespread adoption for now. To make matters worse, when catching an exception, there is no standard way of knowing from where it was thrown. This isn't covered by the C++23 stack trace API either. Even further, in C++, it's possible to throw anything. This makes it impossible to have a base case which can catch all exceptions while still having access to the value. Getting this behavior in the native world requires some clever hacks. Fortunately, Jeremy Rifkin has implemented a very cool library called cpptrace which implements stack traces at arbitrary locations and from arbitrary exceptions.
Let's look at some examples, working from this Clojure source.
(defn -main []
(throw (Exception. "Failed to download file!")))
(-main)
When we run it, we see that Clojure helpfully points out line 3, which is where we call (-main). It doesn't point out the actual line of the throw, but it gives you the last function called before the throw. This is because Clojure is parsing its own stack trace and pulling out the first non-Clojure frame as the source of the error. It only does this when evaluating from the REPL or running a Clojure file as a script, like we are. Clojure won't do this for AOT compiled programs. It'll just show the exception message and stack trace.
Now, jank isn't quite there yet. Given the same source, except we throw the string directly instead of creating a Java Exception, jank gives us this.
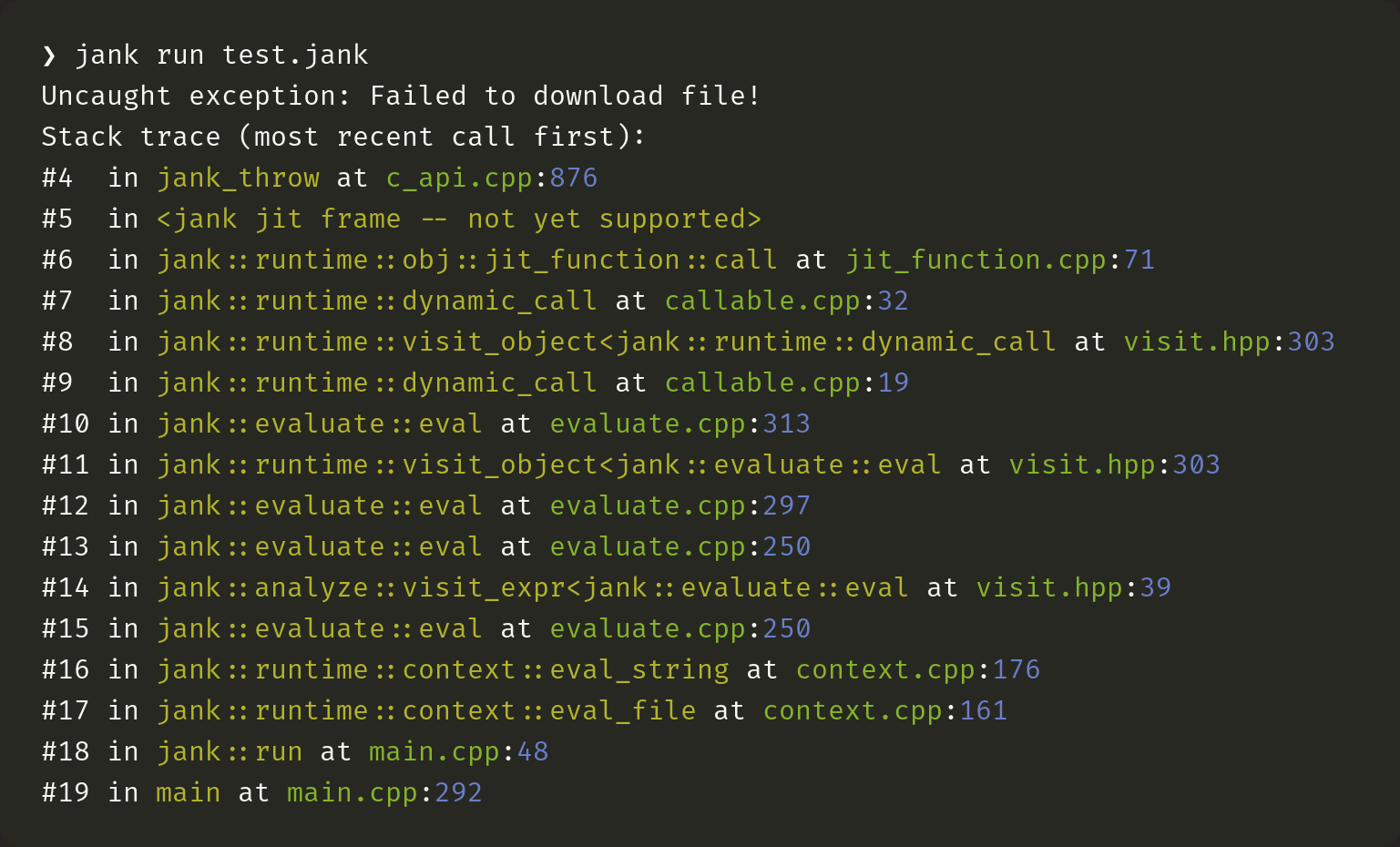
Notably, we don't have source info for the exception here. The reason that we can't right now is that frame #5 is not set, so jank inserts a note that it's not supported yet. This is because the cpptrace library doesn't yet support fetching JIT compiled frame symbols and source info. Jeremy is working on it, though! It shouldn't be a surprise, at this point, to say that C++ has no standard way of registering JIT compiled functions so that tools like cpptrace can access their symbols. In fact, the JIT landscape for C++ is still very green.
Macro expansion exception
So, run-time errors get a stack trace printed, in jank. Compile-time errors get fancy source info with notes. Macro expansion errors span both compile-time and run-time, though, in that macro expansion happens at compile-time, but macros run normal Clojure code in a way which is indistinguishable from run-time. To address this, jank does both forms of error reporting for macro expansion failures. It points at the macro which caused the issue, provides the error which was raised, and then also gives a stack trace.
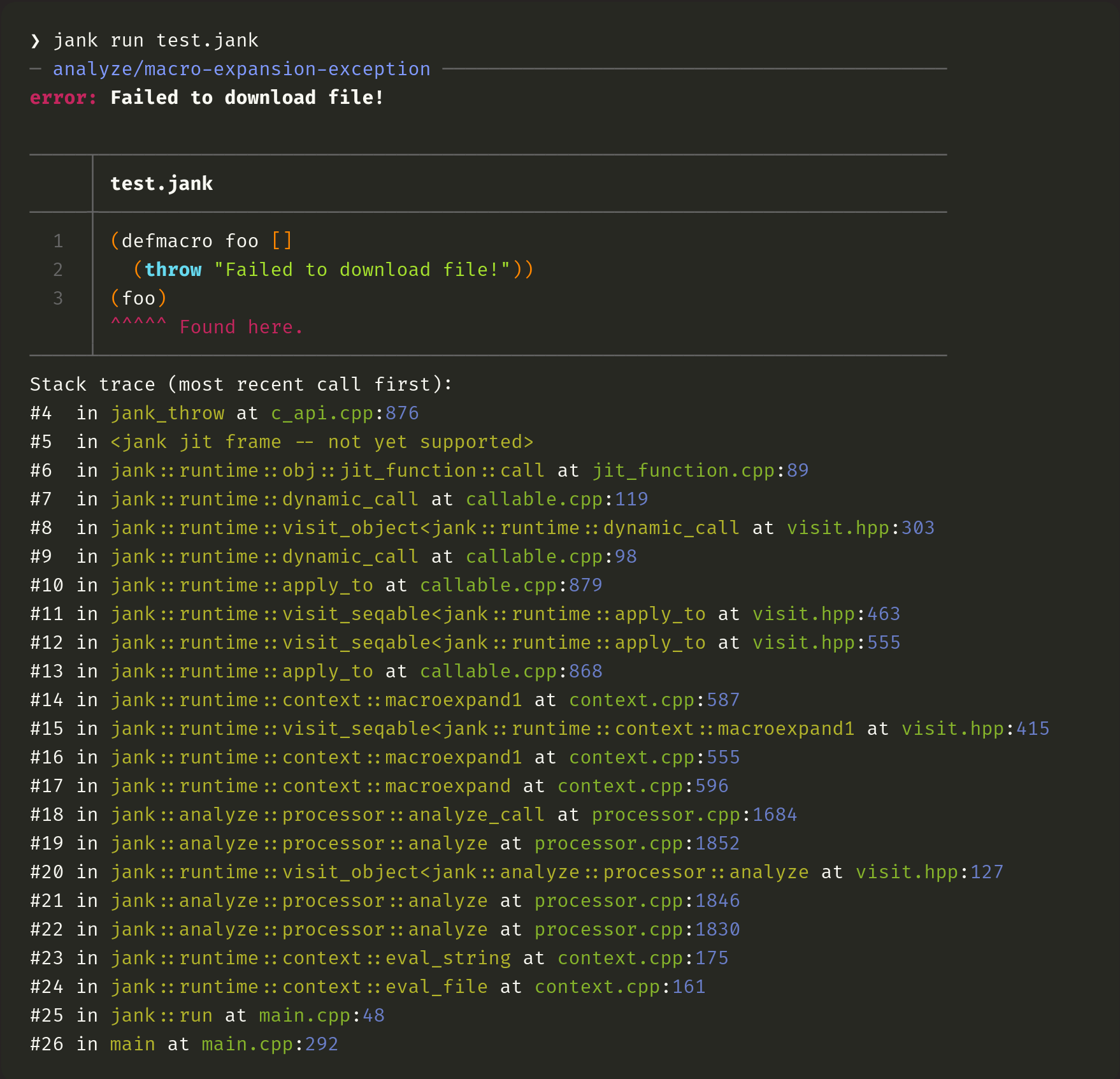
Clojure gives basically the same output regardless of the exception being thrown during macro expansion or normal function evaluation, pointing at the same place (line 3).
Compile-time exception
Finally, we have the last interesting case. If we try to compile some code at run-time, and that fails, jank will try to report it as a compiler error, without the stack trace. This is because jank tries to only show the stack trace for run-time errors. Stack traces are noisy.
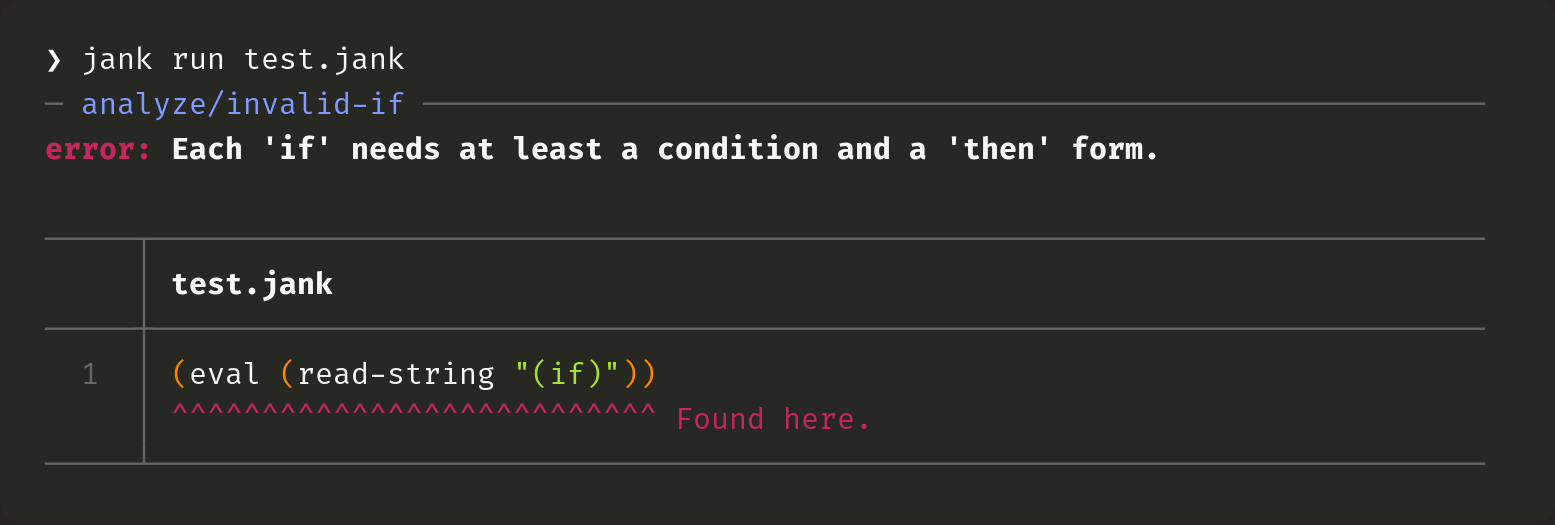
Clojure gives no inclination to this being a special case and reports it just as it did before.

Wrapping up
That was quite the tour of Clojure's error reporting! I think we've clearly identified several ways Clojure can improved. We've also highlighted a couple of areas where jank is still lacking. I want jank to be world-class and I'll keep addressing each of these weaker areas as they're identified. When I started this quarter, I knew I'd be able to match Clojure, but I didn't think I'd be able to achieve this level of helpfulness, polish, and precision. I'm extremely pleased with how the quarter has gone.
Next up
Next quarter, I'm focusing solely on jank's seamless C++ interop. We'll be able to create stack-allocated locals of arbitrary C++ types, access their members, ensure their destructors get called, and even JIT instantiate new templates. The syntax will feel very familiar to existing Clojure users. This level of interop with C++, from a lisp, will be unprecedented. Hang tight for some more updates in the coming weeks!